最近在学习算法,做过的题会提交在这里 我的 LeetCode ,欢迎围观。
数据结构
脑图:https://naotu.baidu.com/file/0a53d3a5343bd86375f348b2831d3610?token=5ab1de1c90d5f3ec
一维:
基础:数组 array (string), 链表 linked list
高级:栈 stack, 队列 queue, 双端队列 deque, 集合 set, 映射 map (hash or map), etc
二维:
基础:树 tree, 图 graph
高级:二叉搜索树 binary search tree (red-black tree, AVL), 堆 heap, 并查集 disjoint set, 字典树 Trie, etc
特殊:
位运算 Bitwise, 布隆过滤器 BloomFilter
LRU Cache
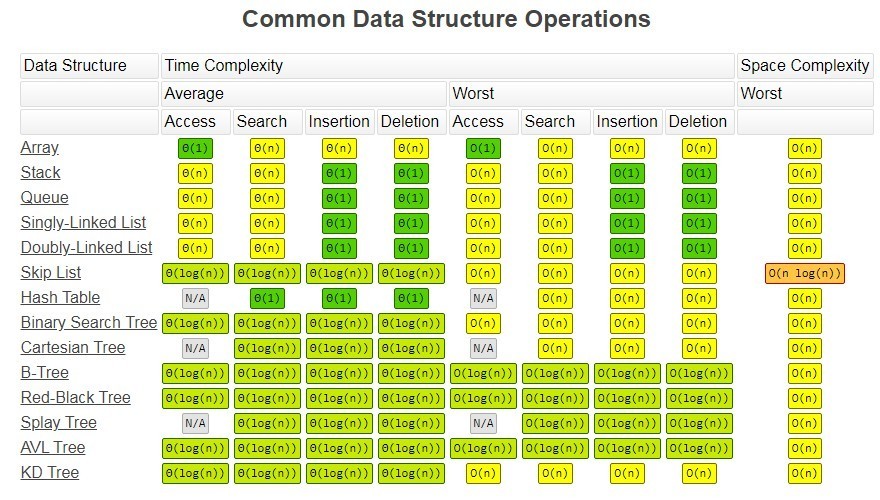
时间复杂度
https://www.bigocheatsheet.com/
算法
If-else, switch —> branch
for, while loop —> Iteration
递归 Recursion (Divide & Conquer, Backtrace)
搜索 Search: 深度优先搜索 Depth first search, 广度优先搜索 Breadth first search, A*, etc
动态规划 Dynamic Programming
二分查找 Binary Search
贪心 Greedy
数学 Math , 几何 Geometry
刷题路线分享
基础
深度优先搜索
回溯
分治
动态规划
部分代码模板 (仅供参考)
并不是题目答案,只是说明大部分题目有套路可循;主要是java、python的版本,或者伪代码,应该能看懂。
递归
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
|
public void recur(int level, int param) {
if (level > MAX_LEVEL) {
return;
}
process(level, param);
recur( level: level + 1, newParam);
}
|
分治、回溯
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
|
private static int divide_conquer(Problem problem, ) {
if (problem == NULL) {
int res = process_last_result();
return res;
}
subProblems = split_problem(problem)
res0 = divide_conquer(subProblems[0])
res1 = divide_conquer(subProblems[1])
result = process_result(res0, res1);
return result;
}
|
DFS
递归写法
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
|
public List<List<Integer>> levelOrder(TreeNode root) {
List<List<Integer>> allResults = new ArrayList<>();
if(root==null){
return allResults;
}
travel(root,0,allResults);
return allResults;
}
private void travel(TreeNode root,int level,List<List<Integer>> results){
if(results.size()==level){
results.add(new ArrayList<>());
}
results.get(level).add(root.val);
if(root.left!=null){
travel(root.left,level+1,results);
}
if(root.right!=null){
travel(root.right,level+1,results);
}
}
|
非递归写法
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
|
def DFS(self, tree):
if tree.root is None:
return []
visited, stack = [], [tree.root]
while stack:
node = stack.pop()
visited.add(node)
process (node)
nodes = generate_related_nodes(node)
stack.push(nodes)
...
|
BFS
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
|
def BFS(graph, start, end):
visited = set()
queue = []
queue.append([start])
while queue:
node = queue.pop()
visited.add(node)
process(node)
nodes = generate_related_nodes(node)
queue.push(nodes)
...
|
贪心算法
贪心算法是在当前情况下做出的最优决定,它只考虑眼前,获得的是局部的最优解,并且,希望通过每次获得局部最优解最后找到全局的最优解。
二分查找
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
|
public int binarySearch(int[] array, int target) {
int left = 0, right = array.length - 1, mid;
while (left <= right) {
mid = (right - left) / 2 + left;
if (array[mid] == target) {
return mid;
} else if (array[mid] > target) {
right = mid - 1;
} else {
left = mid + 1;
}
}
return -1;
}
|
动态规划
DP顺推模板
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
|
function DP():
dp = [][]
for i = 0 .. M {
for j = 0 .. N {
dp[i][j] = _Function(dp[i’][j’]...)
}
}
return dp[M][N];
|
Trie 树(字典树)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
|
class Trie {
private boolean isEnd;
private Trie[] next;
public Trie() {
isEnd = false;
next = new Trie[26];
}
public void insert(String word) {
if (word == null || word.length() == 0) return;
Trie curr = this;
char[] words = word.toCharArray();
for (int i = 0;i < words.length;i++) {
int n = words[i] - 'a';
if (curr.next[n] == null) curr.next[n] = new Trie();
curr = curr.next[n];
}
curr.isEnd = true;
}
public boolean search(String word) {
Trie node = searchPrefix(word);
return node != null && node.isEnd;
}
public boolean startsWith(String prefix) {
Trie node = searchPrefix(prefix);
return node != null;
}
private Trie searchPrefix(String word) {
Trie node = this;
char[] words = word.toCharArray();
for (int i = 0;i < words.length;i++) {
node = node.next[words[i] - 'a'];
if (node == null) return null;
}
return node;
}
}
|
并查集
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
|
class UnionFind {
private int count = 0;
private int[] parent;
public UnionFind(int n) {
count = n;
parent = new int[n];
for (int i = 0; i < n; i++) {
parent[i] = i;
}
}
public int find(int p) {
while (p != parent[p]) {
parent[p] = parent[parent[p]];
p = parent[p];
}
return p;
}
public void union(int p, int q) {
int rootP = find(p);
int rootQ = find(q);
if (rootP == rootQ) return;
parent[rootP] = rootQ;
count--;
}
}
|
布隆过滤器
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
|
public class BloomFilter {
private static final int DEFAULT_SIZE = 2 << 24;
private static final int[] seeds = new int[] { 5, 7, 11, 13, 31, 37, 61 };
private BitSet bits = new BitSet(DEFAULT_SIZE);
private SimpleHash[] func = new SimpleHash[seeds.length];
public BloomFilter() {
for (int i = 0; i < seeds.length; i++) {
func[i] = new SimpleHash(DEFAULT_SIZE, seeds[i]);
}
}
public void add(String value) {
for (SimpleHash f : func) {
bits.set(f.hash(value), true);
}
}
public boolean contains(String value) {
if (value == null) {
return false;
}
boolean ret = true;
for (SimpleHash f : func) {
ret = ret && bits.get(f.hash(value));
}
return ret;
}
public static class SimpleHash {
private int cap;
private int seed;
public SimpleHash(int cap, int seed) {
this.cap = cap;
this.seed = seed;
}
public int hash(String value) {
int result = 0;
int len = value.length();
for (int i = 0; i < len; i++) {
result = seed * result + value.charAt(i);
}
return (cap - 1) & result;
}
}
}
|
LRU Cache
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
203
204
205
206
207
208
209
210
211
212
213
214
215
216
217
218
219
220
221
222
223
224
225
226
227
228
229
230
231
232
233
234
235
236
|
class LRUCache {
private Map<Integer, DLinkNode> cache = new HashMap<>();
private int size;
private int capacity;
private DLinkNode head, tail;
public LRUCache(int capacity) {
this.size = 0;
this.capacity = capacity;
head = new DLinkNode();
tail = new DLinkNode();
head.next = tail;
tail.prev = head;
}
public int get(int key) {
DLinkNode node = cache.get(key);
if (node == null) {
return -1;
}
(node);
return node.value;
}
public void put(int key, int value) {
DLinkNode node = cache.get(key);
if (node == null) {
DLinkNode newNode = new DLinkNode(key, value);
cache.put(key, newNode);
addToHead(newNode);
++size;
if (size > capacity) {
DLinkNode tail = removeTail();
cache.remove(tail.key);
--size;
}
} else {
node.value = value;
moveToHead(node);
}
}
private DLinkNode removeTail() {
DLinkNode node = tail.prev;
removeNode(node);
return node;
}
private void removeNode(DLinkNode node) {
node.next.prev = node.prev;
node.prev.next = node.next;
}
private void addToHead(DLinkNode node) {
node.prev = head;
node.next = head.next;
head.next.prev = node;
head.next = node;
}
private void moveToHead(DLinkNode node) {
removeNode(node);
addToHead(node);
}
private static class DLinkNode {
Integer key;
Integer value;
DLinkNode prev;
DLinkNode next;
DLinkNode() {
}
DLinkNode(Integer key, Integer value) {
this.key = key;
this.value = value;
}
}
}
|
十大经典排序算法
阅读:https://www.cnblogs.com/onepixel/p/7674659.html
图片来源于上文
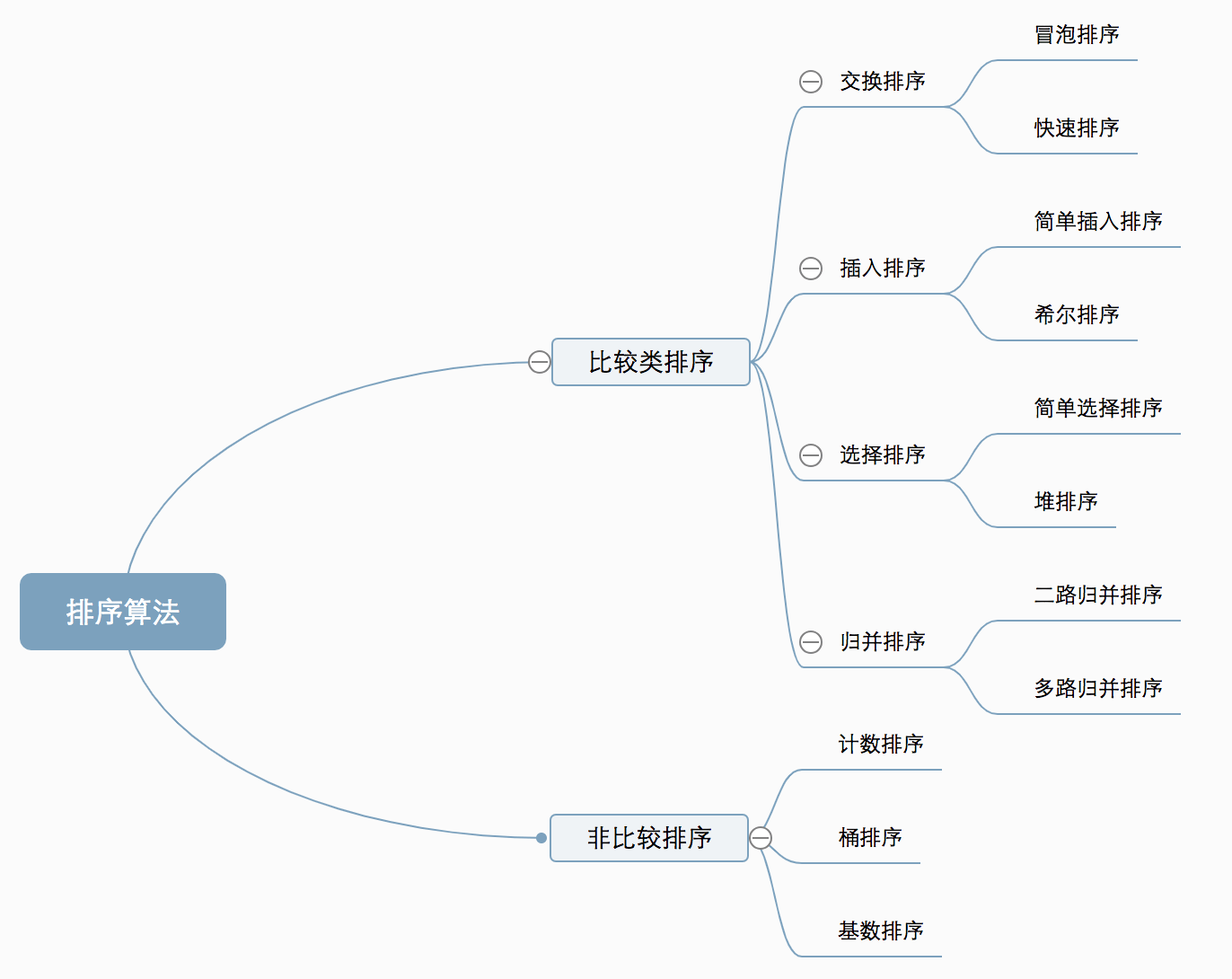
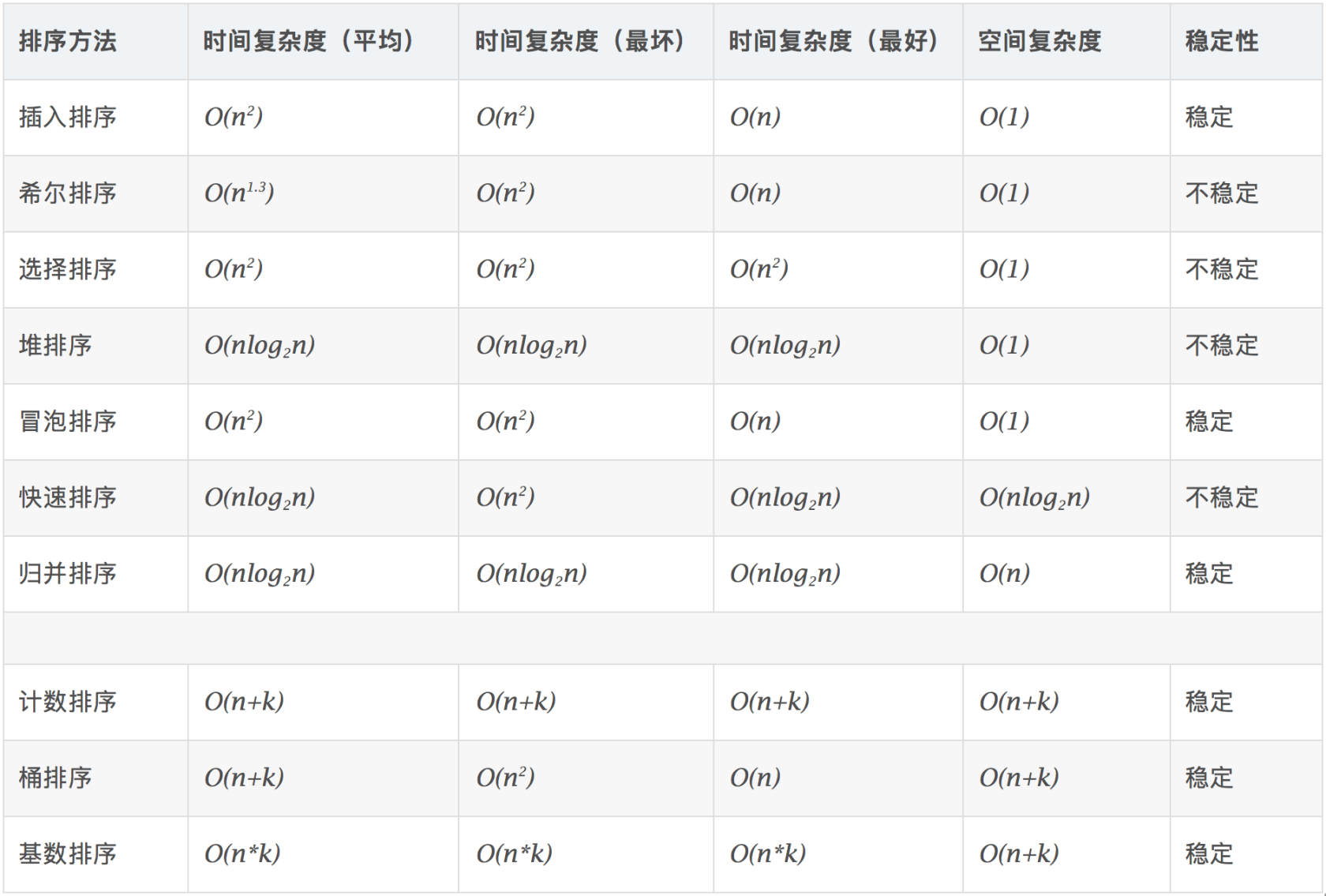
快速排序
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
|
public static void quickSort(int[] array, int begin, int end) {
if (end <= begin) return;
int pivot = partition(array, begin, end);
quickSort(array, begin, pivot - 1);
quickSort(array, pivot + 1, end);
}
static int partition(int[] a, int begin, int end) {
int pivot = end, counter = begin;
for (int i = begin; i < end; i++) {
if (a[i] < a[pivot]) {
int temp = a[counter]; a[counter] = a[i]; a[i] = temp;
counter++;
}
}
int temp = a[pivot]; a[pivot] = a[counter]; a[counter] = temp;
return counter;
}
|
归并排序
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
|
public static void mergeSort(int[] array, int left, int right) {
if (right <= left) return;
int mid = (left + right) >> 1;
mergeSort(array, left, mid);
mergeSort(array, mid + 1, right);
merge(array, left, mid, right);
}
public static void merge(int[] arr, int left, int mid, int right) {
int[] temp = new int[right - left + 1];
int i = left, j = mid + 1, k = 0;
while (i <= mid && j <= right) {
temp[k++] = arr[i] <= arr[j] ? arr[i++] : arr[j++];
}
while (i <= mid) temp[k++] = arr[i++];
while (j <= right) temp[k++] = arr[j++];
for (int p = 0; p < temp.length; p++) {
arr[left + p] = temp[p];
}
}
|
堆排序
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
|
public static void heapSort(int[] array) {
if (array.length == 0) return;
int length = array.length;
for (int i = length / 2-1; i >= 0; i-)
heapify(array, length, i);
for (int i = length - 1; i >= 0; i--) {
int temp = array[0]; array[0] = array[i]; array[i] = temp;
heapify(array, i, 0);
}
}
static void heapify(int[] array, int length, int i) {
int left = 2 * i + 1, right = 2 * i + 2;
int largest = i;
if (left < length && array[left] > array[largest]) {
largest = left;
}
if (right < length && array[right] > array[largest]) {
largest = right;
}
if (largest != i) {
int temp = array[i]; array[i] = array[largest]; array[largest] = temp;
heapify(array, length, largest);
}
}
|
结语
光说不练假把式,重要的是动手做题。