从0到1:搭建一个完整的Kubernetes集群 实践踩坑,涉及一些版本问题。
实验环境
教程提供配置
1 | 2 核 CPU、 7.5 GB 内存; |
实际采用配置
1 | windows下的vm虚拟机: |
安装 kubeadm 和 Docker
教程提供配置
1 | $ curl -s https://packages.cloud.google.com/apt/doc/apt-key.gpg | apt-key add - |
实际解决
国内,用阿里云源安装就可以了,速度很快:
- apt-get update && apt-get install -y apt-transport-https
- curl https://mirrors.aliyun.com/kubernetes/apt/doc/apt-key.gpg | apt-key add -
- 将deb https://mirrors.aliyun.com/kubernetes/apt/ kubernetes-xenial main 加入到下面文件中,没有就创建 /etc/apt/sources.list.d/kubernetes.list
- apt-get update
- apt-get install -y docker.io kubeadm
部署 Kubernetes 的 Master 节点
教程提供配置
1 | apiVersion: kubeadm.k8s.io/v1alpha1 |
2018.09后,出现版本问题的解决办法
kubeadm最新版本已经为1.12,看到上面很多人遇到提示版本不对,重新安装低版本就好了
apt remove kubelet kubectl kubeadmapt install kubelet=1.11.3-00
apt install kubectl=1.11.3-00
apt install kubeadm=1.11.3-00
如果提示kubernetes-cni版本有问题:
apt-get install kubeadm=1.11.3-00 kubelet=1.11.3-00 kubectl=1.11.3-00 kubernetes-cni=0.6.0-00
目前(2019.12)已经是 v1.17.0,尝试重新安装版本:
apt remove kubelet kubectl kubeadm
apt-get install kubeadm kubelet kubectl
配置文件也更新为:
1 | apiVersion: kubeadm.k8s.io/v1beta2 |
实际解决
由于初始化总提示没办法下载 k8s.gcr.io 的镜像,网上很多都是采取先下载google镜像后tag的方法,测试发现google镜像里面暂时还没有v1.17的资源,只有v1.15之前的,为避免环境问题,最终还是回到v1.11,按课程走。
apt remove kubelet kubectl kubeadm
apt-get install kubeadm=1.11.1-00 kubelet=1.11.1-00 kubectl=1.11.1-00 kubernetes-cni=0.6.0-00
下载google镜像
1 | docker pull mirrorgooglecontainers/kube-apiserver-amd64:v1.11.1 |
tag
1 | docker tag docker.io/mirrorgooglecontainers/kube-apiserver-amd64:v1.11.1 k8s.gcr.io/kube-apiserver-amd64:v1.11.1 |
swapoff -a
kubeadm init –config kubeadm.yaml –ignore-preflight-errors=SystemVerification
1 | # 初始化成功!显示以下信息 |
kubeadm 会提示我们第一次使用 Kubernetes 集群所需要的配置命令:
1 | mkdir -p $HOME/.kube |
而需要这些配置命令的原因是:Kubernetes 集群默认需要加密方式访问。所以,这几条命令,就是将刚刚部署生成的 Kubernetes 集群的安全配置文件,保存到当前用户的.kube 目录下,kubectl 默认会使用这个目录下的授权信息访问 Kubernetes 集群。
如果不这么做的话,我们每次都需要通过 export KUBECONFIG 环境变量告诉 kubectl 这个安全配置文件的位置。
常用管理命令
查看当前节的状态
kubectl get nodes
1 | NAME STATUS ROLES AGE VERSION |
在调试 Kubernetes 集群时,最重要的手段就是用 kubectl describe 来查看这个节点(Node)对象的详细信息、状态和事件(Event),我们来试一下:
kubectl describe node ubuntu
另外,我们还可以通过 kubectl 检查这个节点上各个系统 Pod 的状态,其中,kube-system 是 Kubernetes 项目预留的系统 Pod 的工作空间(Namepsace,注意它并不是 Linux Namespace,它只是 Kubernetes 划分不同工作空间的单位):
kubectl get pods -n kube-system
部署网络插件
以 Weave 为例:
1 | kubectl apply -f https://git.io/weave-kube-1.6 |
部署完成后,我们可以通过 kubectl get 重新检查 Pod 的状态:
1 | NAME READY STATUS RESTARTS AGE |
至此,Kubernetes 的 Master 节点就部署完成了。如果你只需要一个单节点的 Kubernetes,现在你就可以使用了。不过,在默认情况下,Kubernetes 的 Master 节点是不能运行用户 Pod 的,所以还需要额外做一个小操作。
部署 Kubernetes 的 Worker 节点
Kubernetes 的 Worker 节点跟 Master 节点几乎是相同的,它们运行着的都是一个 kubelet 组件。唯一的区别在于,在 kubeadm init 的过程中,kubelet 启动后,Master 节点上还会自动运行 kube-apiserver、kube-scheduler、kube-controller-manger 这三个系统 Pod。
所以,相比之下,部署 Worker 节点反而是最简单的,只需要两步即可完成。
第一步,在所有 Worker 节点上执行“安装 kubeadm 和 Docker”一节的所有步骤。
第二步,执行部署 Master 节点时生成的 kubeadm join 指令:
1 | kubeadm join 192.168.139.136:6443 --token 7ypgpe.qzgh5fs0rga7n9bf --discovery-token-ca-cert-hash sha256:bb0bc404012e9b61e905da6cc2f3028f2625c823 2e3d616478b98ba3124558f5 |
通过 Taint/Toleration 调整 Master 执行 Pod 的策略
默认情况下 Master 节点是不允许运行用户 Pod 的。而 Kubernetes 做到这一点,依靠的是 Kubernetes 的 Taint/Toleration 机制。
这部分属于策略配置问题,自行搜索解决。
部署 Dashboard 可视化插件
在 Kubernetes 社区中,有一个很受欢迎的 Dashboard 项目,它可以给用户提供一个可视化的 Web 界面来查看当前集群的各种信息。毫不意外,它的部署也相当简单:
1 | 教程给的地址已失效,以下可用 |
由于本次实验是vm里面的虚拟机,windows主机无法访问dashboard,教程提到:如果想从集群外访问这个 Dashboard 的话,需要用到 Ingress。
部署容器存储插件
Kubernetes 集群的最后一块拼图:容器持久化存储。
很多时候我们需要用数据卷(Volume)把外面宿主机上的目录或者文件挂载进容器的 Mount Namespace 中,从而达到容器和宿主机共享这些目录或者文件的目的。容器里的应用,也就可以在这些数据卷中新建和写入文件。
由于 Kubernetes 本身的松耦合设计,绝大多数存储项目,比如 Ceph、GlusterFS、NFS 等,都可以为 Kubernetes 提供持久化存储能力。在这次的部署实战中,教程选择部署一个很重要的 Kubernetes 存储插件项目:Rook。
Rook 项目是一个基于 Ceph 的 Kubernetes 存储插件(它后期也在加入对更多存储实现的支持)。不过,不同于对 Ceph 的简单封装,Rook 在自己的实现中加入了水平扩展、迁移、灾难备份、监控等大量的企业级功能,使得这个项目变成了一个完整的、生产级别可用的容器存储插件。
得益于容器化技术,用两条指令,Rook 就可以把复杂的 Ceph 存储后端部署起来:
1 | kubectl apply -f https://raw.githubusercontent.com/rook/rook/master/cluster/examples/kubernetes/ceph/operator.yaml |
这样,一个基于 Rook 持久化存储集群就以容器的方式运行起来了,而接下来在 Kubernetes 项目上创建的所有 Pod 就能够通过 Persistent Volume(PV)和 Persistent Volume Claim(PVC)的方式,在容器里挂载由 Ceph 提供的数据卷了。
而 Rook 项目,则会负责这些数据卷的生命周期管理、灾难备份等运维工作。
可能遇到的问题
master宕机重启后引起的coredns Error:
1 | kubectl -n kube-system get deployment coredns -o yaml | \ |
尝试将work节点加入master的过程:
1 | token可能过期 |
实验结论
实际上,整个k8s集群,只成功部署了master(包括网络插件、可视化插件、存储插件),在worker join的过程,也提示docker版本的问题,忽略之后,有提示该节点已加入集群,如下: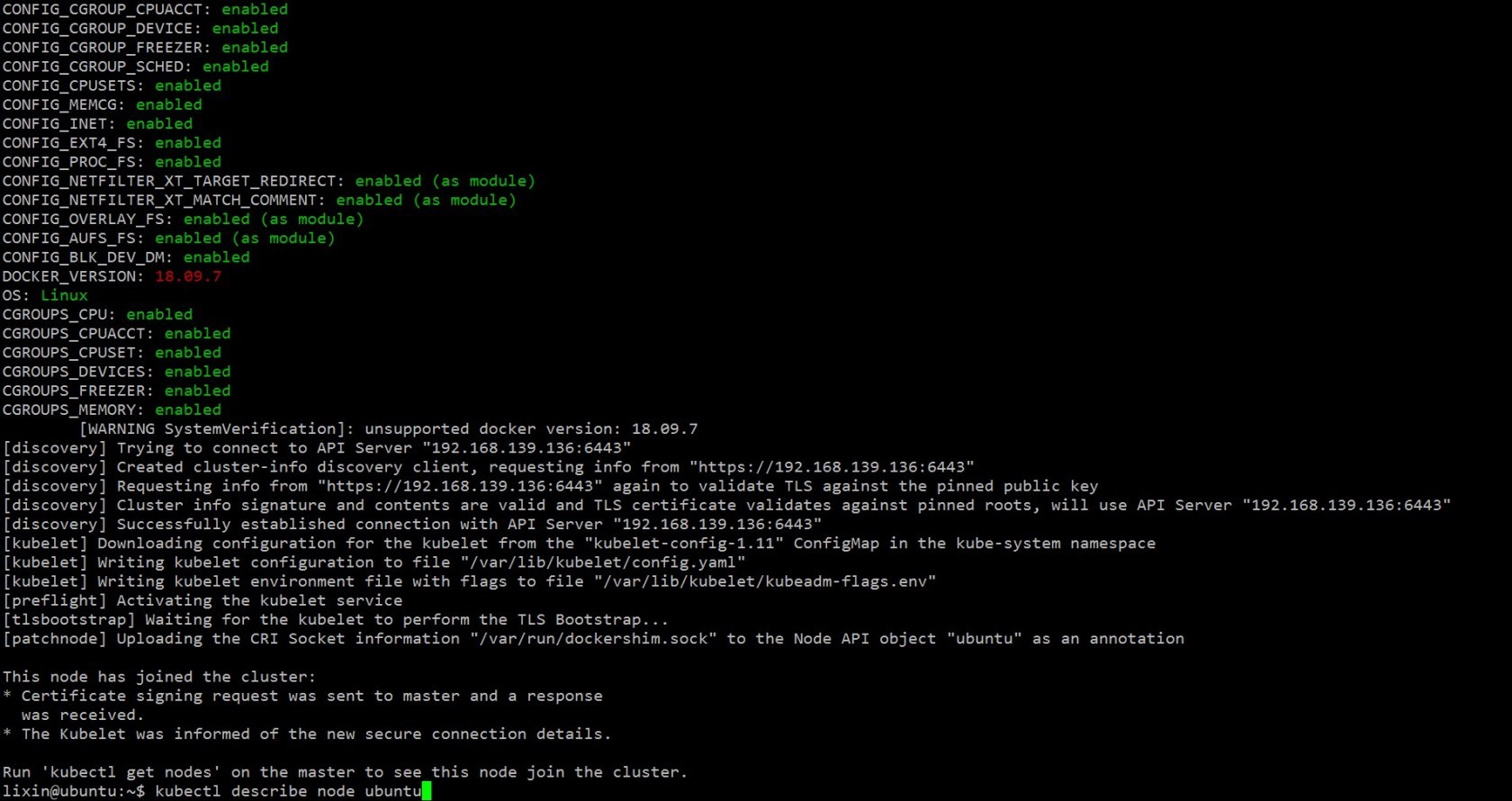
但master上始终没看到worker的信息。查看master的日志,如下:
从上面信息来看,个人认为是版本问题,毕竟v1.11.1是一年前的版本。
我尽力了,虽然暂时没有成功,或者等我学习更多k8s的知识,我能解决目前的问题。
如果有基于ubuntu16.04、k8s v1.11.1搭建成功的小伙伴,也可以给我留言。
其实网上有很多基于centos搭建成功的,可以参考。